Posts
Profiling Jupyter Notebook Code with py-spy
jupyter
py-spy
performance
python
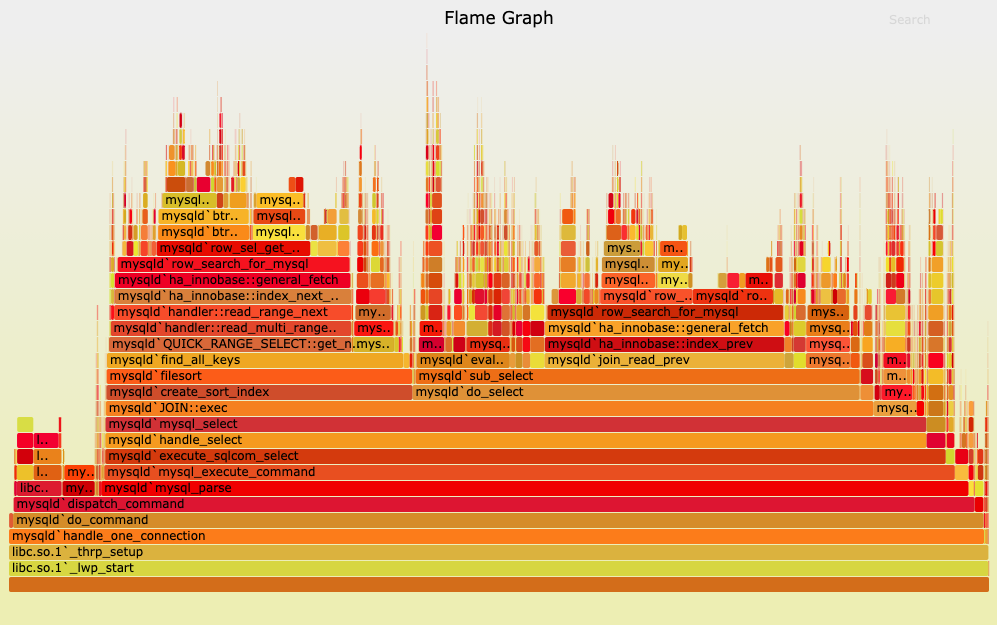
When you sync your Jupyter notebooks with Jupytext, you get to keep all the benefits of Jupyter notebooks while also being able to pass your code through a profiler like py-spy to get a rich, interactive visualization that helps you quickly understand where the bottlenecks are.
Comparing Collaborative Filtering Methods
recommender systems
collaborative filtering
python
numpy
pandas
seaborn
jupyter
matplotlib
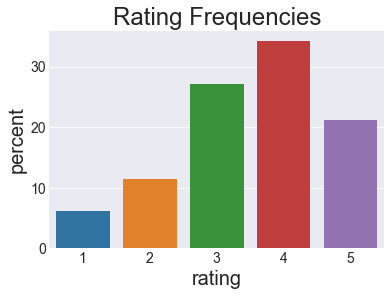
I wanted to dive into the fundamentals of collaborative filtering and recommender systems, so I implemented a few common methods and compared them.
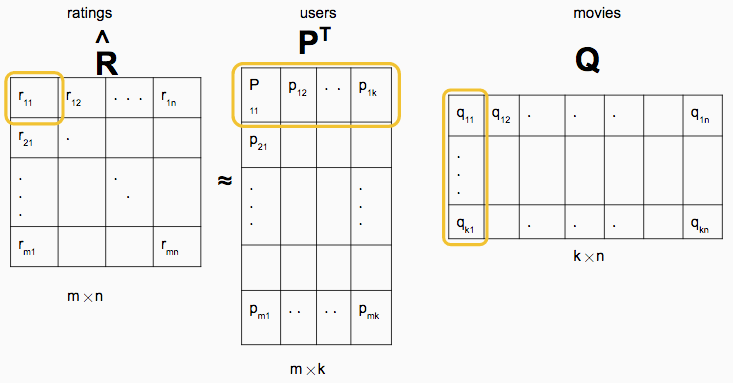
Taking Advantage of Sparsity in the ALS-WR Algorithm
python
machine learning
collaborative filtering
recommender systems
A little tweak to some code from a great tutorial speeds up computation by taking advantage of sparsity
No matching items